
Do LLM Products Need Their Own File System?
What would that file system look like?

Welcome to Infinite Curiosity, a newsletter that explores the intersection of Artificial Intelligence and Startups. Tech enthusiasts across 200 countries have been reading what I write. Subscribe to this newsletter for free to directly receive it in your inbox:
One question I've been thinking about recently: DO LLM-BASED PRODUCTS NEED THEIR OWN FILE SYSTEM?
Why isn't a regular file system good enough?
Traditional file systems assume lots of small reads and writes. LLM training and serving do huge sequential reads on gigantic files. And there's the occasional multi-gigabyte checkpoint writes. So the regular file system misses the mark.
How would we lay out the data on disk?
We'd have to group the tokens into large fixed-size shards (a shard is a partition of a large database). And then store them in append-only blocks. An embedded index file maps each shard to its byte range so the model can jump straight to the right chunk without scanning the whole corpus.
How do we make checkpoints painless?
We should use copy-on-write snapshots. What it means is that only the blocks that actually change get duplicated. This turns a 300 GB save into a few gigabytes of new data and lets you roll back any run in seconds.
It basically freezes the current state of the data by simply marking existing blocks as shared. So taking the snapshot is almost instant and uses almost no extra space. When something later changes, the system writes the new data to fresh blocks and leaves the original blocks untouched. And this lets you roll back to the exact snapshot any time.
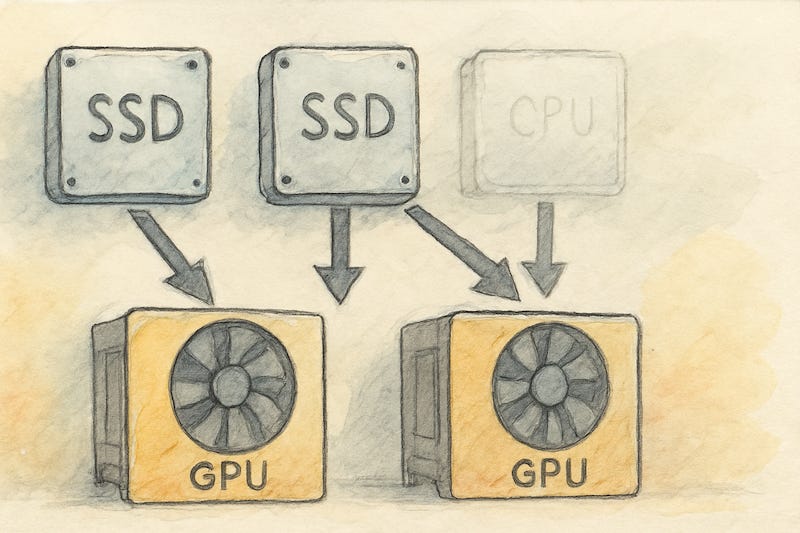
How do we feed dozens of GPUs at once?
Spread each data chunk across several super-fast SSDs. And let every GPU grab its data straight from those drives. This skips the central computer bottleneck, so nothing gets slowed down.
How do we keep costs sensible as models grow?
"Cold" tiers could be useful here. Move the rarely-used shards and old checkpoints to cheap object storage. But you should cache "hot" shards on fast local SSDs. A simple tiering policy could be something like “demote after 21 days of no access”. This keeps the costs in check.
If you're a founder or an investor who has been thinking about this, I'd love to hear from you.
If you are getting value from this newsletter, consider subscribing for free and sharing it with 1 friend who’s curious about AI: