
How Do Long-Running Agents Work?
What's the venture opportunity, How do we go from stateless web to a living loop

Welcome to Infinite Curiosity, a newsletter that explores the intersection of Artificial Intelligence and Startups. Tech enthusiasts across 200 countries have been reading what I write. Subscribe to this newsletter for free to directly receive it in your inbox:
The first era of generative AI was defined by the session. You opened a tab, you prompted, the model replied, and when you closed the window that “mind” evaporated. Brilliant, but ephemeral. Transactional intelligence.
Long-running agents are the opposite. Are they just chatbots with better memory then? Not exactly. They’re persistent digital entities that maintain continuity of existence, reasoning, and identity over indefinite periods. Instead of just responding, they inhabit a process.
This is the real threshold we’re crossing: from request–response to persistence of thought.
Beyond Request–Response: From Stateless Web to a Living Loop
To understand long-running agents, you have to unlearn the statelessness baked into modern software. Traditional web patterns assume a synchronous call: request in, response out, the server forgets.
Most LLM products inherited this shape. The model is effectively frozen in time. It has no concept of waiting or working unless you push tokens into it.
A long-running agent breaks that dependency. Architecturally, it runs a loop:
Perception → Reasoning → Action → Wait
And it keeps doing this without needing you present. It can wake on events (webhooks, emails, alerts), schedule itself (cron), sleep for hours, then resume exactly where it left off. The user expresses intent once. The agent manages the temporal execution.
This shift is bigger than UX. It’s the move from:
Assistant (waits for a command)
toAgent (pursues a goal)
So what’s the core product if it isn’t a chat window? It’s a scheduler, a task inbox, a state store, and a runtime that doesn’t die when the tab closes.
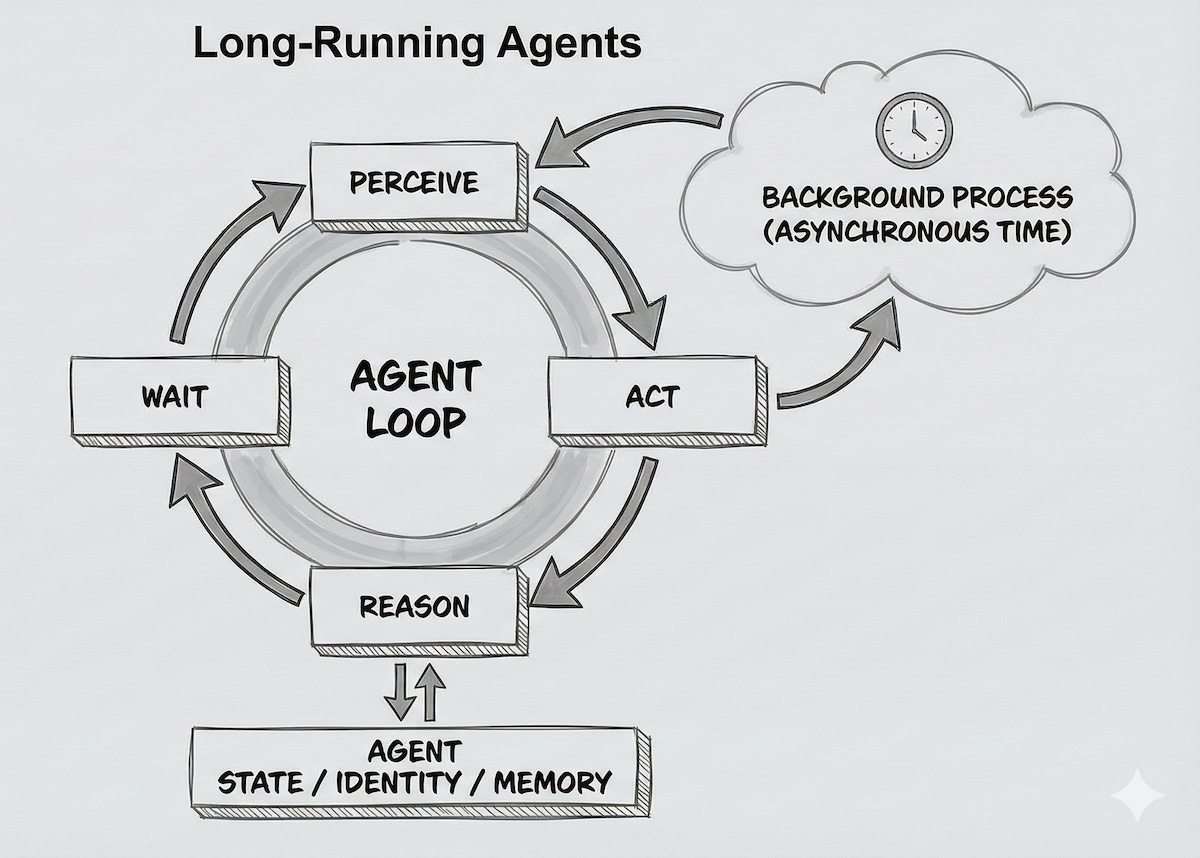
Background Agents: Asynchrony Is the First Superpower
The most immediate instantiation is the background agent. In systems terms, this is the difference between a synchronous function call and a background job queue. But applied to cognition.
Give a transactional bot: “Plan a vacation.” It will spit out an itinerary from priors.
Give a long-running agent the same goal and it behaves like a persistent worker. It might:
watch flight prices for days and react to drops
ping hotels for a specific amenity and wait for replies
refine the plan based on constraints you add mid-stream
surface only the moments that require your decision
The important part isn’t that it can browse. It’s that it can handle blocking tasks like waiting on humans, network calls, compilations, and approvals. And it’s doing this without timing out the interface or collapsing its internal thread.
The agent thinks longer.
Identity: Continuity Under Mutation
When something runs for weeks, “identity” stops being personality. It becomes continuity under mutation.
If you don’t explicitly engineer identity, you don’t get one agent. You get a chain of loosely-related sessions pretending to be coherent.
A durable agent identity usually has three pillars:
Core directive (immutable)
What it’s allowed to optimize
What it must never violate
The purpose that survives tool changes and context window resets
Episodic memory (history)
A record of decisions, actions, outcomes, and failures.
The antidote to looping (the classic “AutoGPT spins forever” problem).
The substrate for reputation: has this agent earned trust?
State management (rehydration)
The current “mental snapshot”: active tasks, pending approvals, partial plans.
If the process crashes, the agent must restart and continue without duplicating side effects (“already booked the flight, next step is car rental”).
Without these, “long-running” is just a script running in a loop. Identity is what gives the agent trajectory.
Memory: Not More Memory, But Better Memory Semantics
Long-running agents turn memory into a systems problem. Not “add a vector DB,” but: what kinds of memory exist? and what are their read/write contracts?
You want at least 4 buckets:
Working memory: what matters right now for the current step
Episodic memory: what happened (events, decisions, outcomes)
Procedural memory: how to do things (playbooks, workflows, tool recipes)
Normative memory: invariants (policies, preferences, constraints)
Most stacks collapse these into one retrieval soup. Over time, that becomes a junk drawer. Then drift begins: irrelevant details get over-weighted, invariants get diluted, and a single wrong “fact” can propagate forward for weeks.
Memory hygiene becomes table stakes:
typed writes (structured events, structured decisions)
constrained reads (retrieve only what the plan can justify)
provenance (where did this belief come from, is it trusted?)
garbage collection (summarize, compress, archive)
If you can’t answer “why did the agent believe X”, then perhaps you don’t have an agent. It’s just a liability.
Reasoning Over Time: Slow Thinking, Reflective Control Flow
So is “better reasoning” the profound change here? Yes, but there’s more. It’s reasoning over time.
A long-running agent can afford slow thinking. It can do reflective loops:
simulate an action
critique the plan
search docs
write tests
fail the tests
revise
repeat until it converges
That’s not a prompt trick. It requires explicit control flow. Long-running agents are closer to state machines and DAGs than to chat transcripts. The model is the policy engine that selects transitions. But the system provides the graph, the checkpoints, and the guardrails.
This is also where post-training techniques (and RL, when you have objective signals like tests/spec compliance) actually matter: not to make the agent “more autonomous,” but to tune decision policies under constraints.
The Trust Boundary: Drift, Observability, and Interruptibility
If an agent acts on your behalf for a week, you’re running an alignment problem in microcosm. The central risk is drift (not hallucination).
How do you ensure a persistent agent hasn’t slowly moved away from your original intent? How do you know it’s not silently accumulating wrong beliefs, or optimizing the wrong proxy, or becoming overconfident in a shaky plan?
Two requirements drop out:
Observability (“dashboard of thought”)
Not raw chain-of-thought dumping, but legible traces:
current plan, next action, success criteria
what it believes and why (provenance)
what it tried, what failed, and what it learned
Replayability matters. You want an audit trail you can re-run.
Interruptibility
You must be able to inject constraints mid-flight:
“Don’t book yet”
“Cap spend at $X”
“Escalate if uncertain”
And the agent must incorporate this without losing progress or corrupting state.
This is runtime governance.
So What’s The Startup Opportunity Here?
Bounded execution is the venture opportunity here. Once agents run in the background, the runtime becomes the product.
You need governors that are enforced, not suggested:
capability-based permissions (scoped tokens per task, not god-mode)
tool allowlists and action gating for high-impact steps
budgets (tokens, dollars, time, side-effecting calls)
idempotency and transactional writes (so retries don’t multiply damage)
checkpoints, rollbacks, and safe failure modes
This is why “agent = model” is the wrong abstraction. Agent = process with a brain is closer. The LLM is the reasoning component. The infra is what makes it durable.
Conclusion: The Persistent Colleague
We’re moving toward a world where you don’t “use” AI tools in sessions. You coexist with persistent digital colleagues. Agents that have been running for years, quietly maintaining continuity: tracking a project’s history, watching infra costs, monitoring markets, keeping systems healthy.
Long-running agents are the maturation step from parlor trick to workforce. They turn intelligence into a utility that doesn’t spark only when you touch it. It hums persistently in the background, with identity, memory, slow reasoning, and a trust boundary you can actually operate.
The punchline stays simple: long-running agents are persistent processes that survive time.
If you are getting value from this newsletter, consider sharing it with 1 friend who’s curious about AI:
The memory hygiene section is underrated. Most agent demos focus on retrival but ignore cleanup and the garbage collection problem gets worse as runtime extends. I've seen production systems where agents accumilate contradictory beliefs over days because noone thought about memory eviction policies beyond basic LRU.