
Neural Operators for Software Infra
Why the real alpha could be in "infra physics" and not physical simulation

Welcome to Infinite Curiosity, a newsletter that explores the intersection of Artificial Intelligence and Startups. Tech enthusiasts across 200 countries have been reading what I write. Subscribe to this newsletter for free to directly receive it in your inbox:
Neural Operators (NOs) are models that learn mappings between functions, not just mappings between fixed-length vectors. In the classic framing, the “function” is a physical field (pressure, velocity) and the operator approximates a PDE (partial differential equation) solver.
In our new framing, the “function” is system state: memory pages, CPU scheduler queues, dependency graphs, build artifacts, logs, request traces, cache state, and model training signals (loss, gradients, optimizer state).
The operator we care about is no longer “Navier–Stokes → next timestep.” It’s:
Stateₜ + Actionₜ → Stateₜ₊₁ + Observablesₜ₊₁
Where Action could be a code diff, a shell command, an agent tool call, a hyperparameter config, a compiler pass sequence, or a scaling decision. And Observables are the things infra teams actually optimize against: error classes, stack traces, latency, cost, convergence, throughput, and failure probability.
The unlock is time. In modern infra, “can we run the code” is less likely to be the bottleneck. The bigger bottleneck usually takes the shape of “how fast can we learn what will happen.” Agents and post-training pipelines are dominated by ground truth execution loops: build, run, fail, parse, retry. Neural operators offer a path to neural simulation: predicting environment outcomes in milliseconds without paying the full execution cost.
Here is the contrarian thesis: treat computing as a physical system with laws (conservation of resources, queuing, contention, interference).
Neural Operators learn those laws and become a new infra primitive. An “infra physics engine” that compresses feedback loops by orders of magnitude.
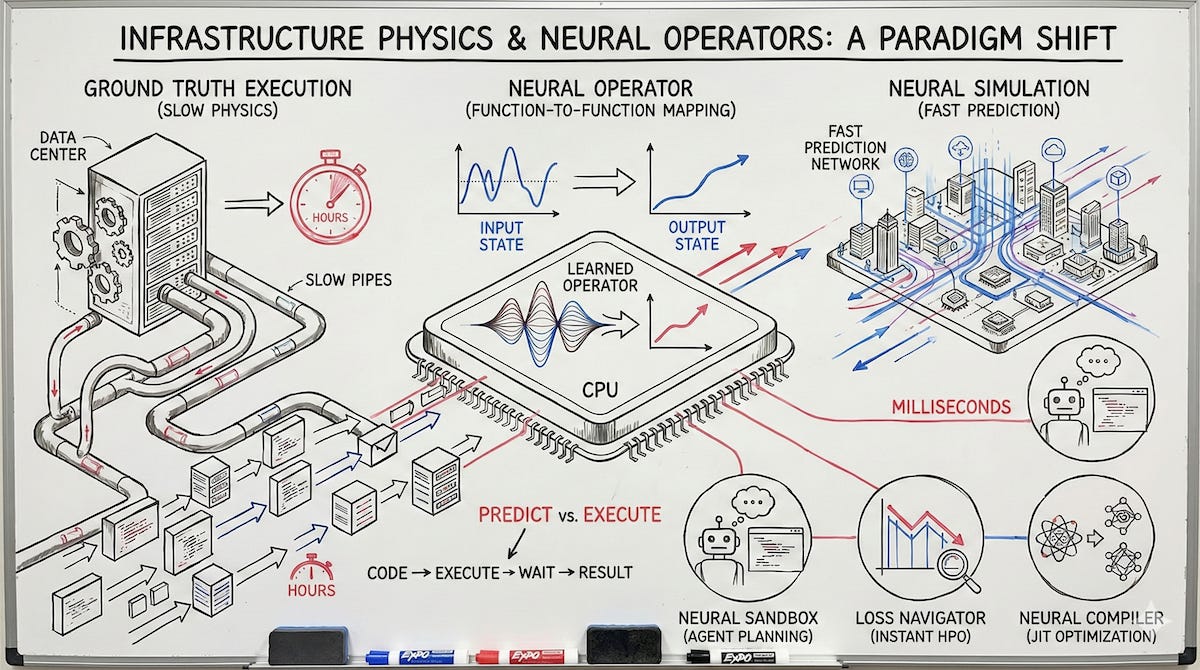
The Proof Point: From Ground Truth Execution to Neural Simulation
The proof point in physical simulation was speedups against PDE solvers. The proof point here is the same phenomenon, but the “solver” is ground truth execution in software.
Two places the pain is existential:
Agent execution speed
Coding agents are slow because they must repeatedly execute in sandboxes: provision container, install deps, compile, run, capture logs, interpret errors, patch, rerun. The dominant cost is environment interaction latency and variance (not token inference). If you could replace 80% of those exec calls with fast, reliable predictions, you fundamentally change the slope of agent productivity. Is the “speedup” then 10,000x of a fluid solver? That’s not what I’m talking about. It’s moving from seconds/minutes per iteration to milliseconds. And enabling rollouts that are currently infeasible (50-step plans, branching search, self-debugging at scale).LLM post-training cost
Post-training is “expensive uncertainty.” You don’t know whether a run will converge, collapse, or plateau until you’ve paid a meaningful fraction of the cost. Teams burn massive GPU budgets learning basic truths about configs, data mixes, reward models, and optimizer schedules. This is exactly what Neural Operators are good at. They learn the operator that maps “initial conditions” to “trajectory.” If you can predict training dynamics early, you turn training from a blind flight into an instrumented, simulated control problem.
The meta-proof point is that both domains are state evolution problems with long-horizon drift. Transformers are not built to model stable state transitions across many steps; Neural Operators explicitly are.
Market Shape: Infra as the True Prize
The physical simulation market is real, but crowded and increasingly incumbent-shaped. Infra Physics is different. It attacks the cloud infra + devops + model ops budget where (a) spend is massive (b) buyers are technical (c) workflows are already software-defined.
This market is anchored by:
CI/CD and build systems (where every minute of feedback loop costs real engineering throughput)
Kubernetes + autoscaling (where misprediction and cold starts cost SLO breaches and revenue)
Observability stacks (logs, traces, metrics) as the substrate for learning system dynamics
Compiler and kernel optimization (where performance is money, especially on GPUs)
Training infra (experimentation platforms, HPO, eval harnesses, deployment gating)
The “incumbents” are not Ansys and Siemens. They’re the current primitives such as deterministic sandboxes, reactive autoscalers, heuristic compilers, brute-force HPO, and human-in-the-loop debugging. These systems work, but they’re fundamentally non-predictive. They wait for reality to happen and then respond.
Infra Physics flips that. It makes infra predictive by learning the operator of the system. The wedge is inserting a “fast surrogate layer” at the highest-frequency decision points.
Customers: Foundation Model Labs + Platform Engineering Teams
The initial customers are the ones who feel execution cost as existential.
Foundation model labs (and their training orgs)
Their job is to ship model improvements faster while managing runaway compute cost. They will pay for anything that reduces wasted runs, increases experiment velocity, and improves training reliability. The budget owners sit in research engineering, training infra, and model ops.Platform engineering teams at scaled software companies
Their job is to compress developer feedback loops and defend production SLOs. They own CI, developer experience, release pipelines, infra reliability, and cost management. They care about faster “time-to-merge”, fewer flaky builds, pre-flight safety checks for agent actions, predictive scaling, and performance regressions.
Tooling vendors building agents
Any company shipping coding agents, data agents, or workflow agents needs predictable, low-latency environment interaction. They are structurally incentivized to buy a surrogate layer because it increases agent throughput and reduces infra spend.
The job to be done across all of them is the same: accelerate feedback loops.
Product Stack: The Neural Sandbox, Training Dynamics, and Compiler Flows
The product stack in Infra Physics looks like a set of “operator layers” sitting on top of telemetry.
a) Neural Sandbox (World Model for Agents)
A neural surrogate of the runtime environment. It takes repo state + environment state + action (diff/command) and predicts next-state + outcomes (error type, output class, dependency conflicts, test failures). Agents call predict_exec() far more often than exec(). The value prop is branching search and long-horizon planning without paying the full cost of reality.
b) Loss Landscape Navigator (Post-Training Infra)
A training dynamics simulator. It takes initial conditions (checkpoint metadata), config, and data statistics and predicts trajectories (loss, KL, reward, gradient norms) plus divergence risk. This becomes “instant HPO,” early stopping, and compute allocation control. It turns training into a “simulated control plane” rather than brute-force exploration.
c) Neural Compiler (Optimization-as-a-Service)
A graph operator that predicts the optimized transform. It learns mappings from unoptimized IR (intermediate representation) → optimized IR conditioned on target hardware and observed execution traces. This becomes a JIT optimizer for GPUs and accelerators, a wedge into kernel-heavy workloads and training pipelines.
Compute substrate remains GPUs (and increasingly specialized accelerators). But the application is no longer simulating atoms. It’s simulating information flow.
Company Map: Three Venture-Scale Startup Opportunities
Are we just underwriting incremental dev tools here? Not exactly. We’re underwriting new infra primitives":
Startup A: The Neural Sandbox (World Models for Agents)
What it is: A “dreaming environment” API for coding agents that predicts execution outcomes without execution.
Core operator: State + Action → Next State + Observables across repo + runtime + dependency graph.
Why it wins: Agents are bottlenecked by environment latency. If you speed up environment interaction, you speed up everything: planning, debugging, exploration, and safe autonomy.
Business model: Usage-based API + enterprise deployments (VPC/on-prem), priced on developer minutes saved and infra cost avoided.
Why now: Agent adoption is rising, and every serious deployment quickly hits sandbox scaling and latency pain.
Startup B: The Loss Landscape Navigator (Post-Training Infra)
What it is: A simulator for training dynamics that predicts whether a run will converge, how quickly, and what it will likely yield.
Core operator: Initial conditions + config + data stats → training trajectory function.
Why it wins: Post-training spend is huge and experimentation is expensive. This product becomes the “risk engine” that decides which runs get compute.
Business model: Enterprise platform with deep integrations into training stacks. Priced on avoided GPU waste and faster iteration.
Why now: The industry is shifting from “train once” to “iterate continuously.” Post-training is becoming the main compute sink.
Startup C: The Neural Compiler (Optimization-as-a-Service)
What it is: A learned optimization layer that generates optimized IR / pass sequences for specific hardware targets.
Core operator: IR graph → optimized IR graph conditioned on traces + hardware constraints.
Why it wins: Compiler optimization is a massive, under-automated surface area. GPU kernels and training pipelines are money-printing workloads where single-digit % gains are worth tens of millions.
Business model: Per-seat/per-build licensing + performance-share pricing for high-value workloads.
Why now: Hardware is fragmenting and traditional compiler heuristics can’t keep up. Performance engineering is becoming a bottleneck.
GTM: Developer Adoption, CI/CD Insertion, and “Trust via Evaluation”
Physical simulation sells through trust and domain incumbents. Infra Physics sells through developer workflows.
Primary GTM motion: land inside CI/CD
The wedge is to intercept the expensive loops.
pre-merge: predict test failures, dependency conflicts, build breaks
pre-deploy: predict perf regressions, latency spikes, cost explosions
agent guardrails: predict whether an action is safe before executing
This is a classic dev tools GTM: start as a narrow plugin (GitHub Actions, Buildkite, Jenkins, Bazel), prove ROI in days, and expand laterally.
The trust barrier is surrogate accuracy
Here, “trust” means: does predict_exec() lie? If it lies, it can cause silent failures or wasted time. So the product must ship with:
calibrated uncertainty (“I don’t know” paths that fall back to ground truth)
continuous evaluation harnesses
drift detection as environments change (deps, versions, infra updates)
adversarial testing (agents will exploit loopholes)
Need to treat evaluation as part of the product.
Moats and Risks: Telemetry Flywheels vs Hallucination Catastrophe
Defensibility
The moat here is the telemetry:
build logs, test outcomes, dependency resolution traces
training run curves across configs and datasets
compiler traces and kernel performance signatures
production traces (latency fields, contention patterns)
Whoever sits closest to the data flywheel builds the best operator. That creates a compounding advantage: more integrations → more telemetry → better predictions → more adoption.
The second moat is workflow embedding. If you become the predictive layer inside CI and agent runtimes, ripping you out is disruptive. That’s real lock-in.
Bottom line
Infra Physics is a bet that the next generation of infra will be predictive. Neural Operators are the right mathematical shape for long-horizon state evolution. If you can build reliable surrogates of execution, training dynamics, and compiler behavior, you create venture-scale primitives that sit at the highest-frequency bottlenecks in the modern software economy.
If you are getting value from this newsletter, consider sharing it with 1 friend who’s curious about AI: