


What Is A Tensor In Machine Learning
What exactly is it. Why is it relevant. Where is it used.

Hey reader, welcome to the 💥 free edition 💥 of my weekly newsletter. I write about ML concepts, how to build ML products, and how to thrive at work. You can learn more about me here. Feel free to send me your questions and I’m happy to offer my thoughts. Subscribe to this newsletter to receive it in your inbox every week.
If you're in machine learning, you've certainly come across the word tensor. It has become an integral part of machine learning. Google built their flagship machine learning library around this concept and called it TensorFlow.
We've been using the concept of tensors for a long time in other domains. But what exactly is a tensor? And why is it relevant to machine learning?
Why do we need tensors?
In ML, we need data to build models. The data needs to be represented using a structure that lends itself well to training those models. We're familiar with scalars and vectors, but they are low dimensional data structures.
In modern ML, data tends to be high dimensional. So we need a data structure that can natively handle being high dimensional. That's where the concept of tensor comes in.
What is a tensor?
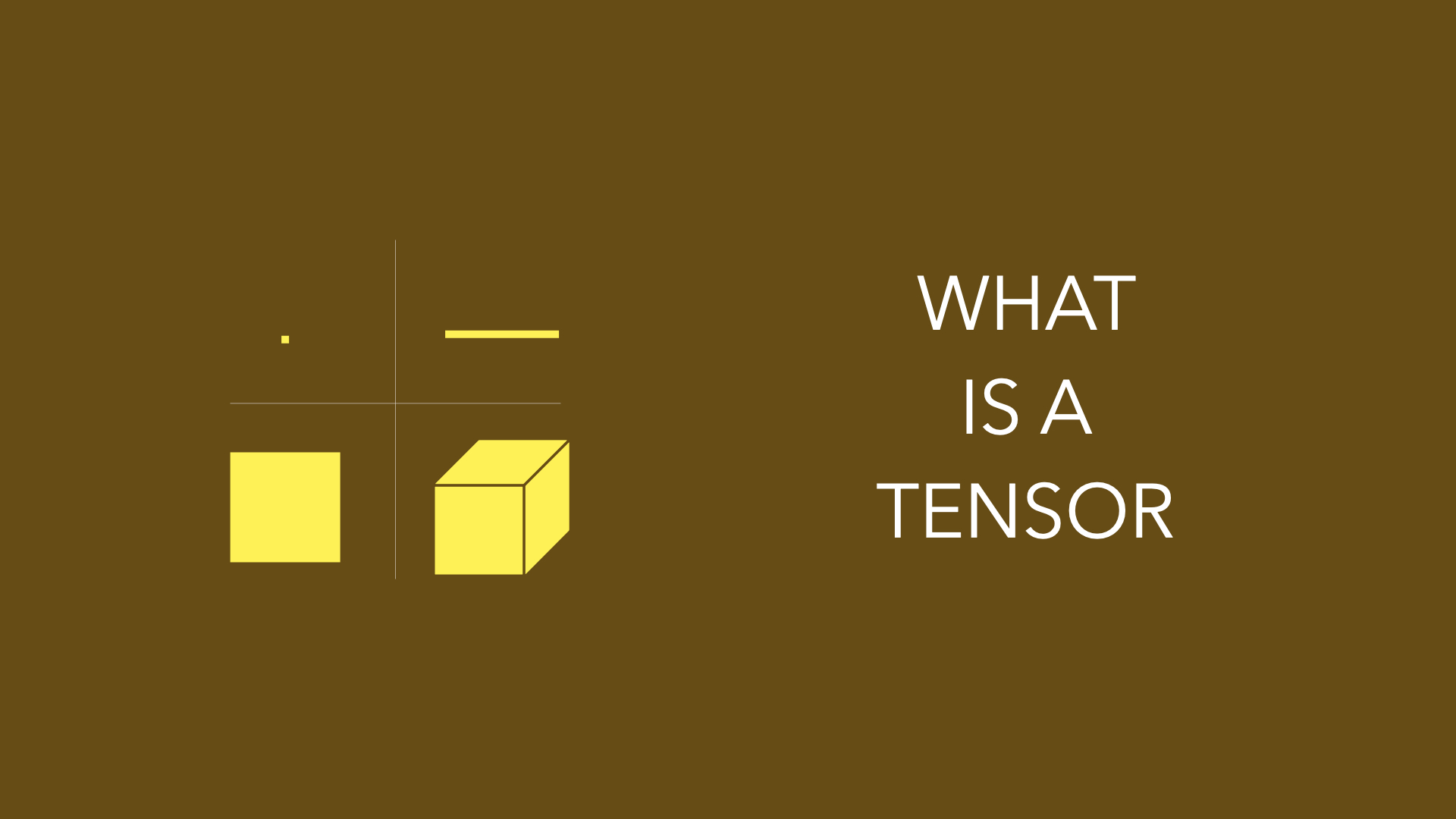
Simply put, a tensor is a data structure with dimensions. It has become the go-to data structure to build ML models. We already know specific forms of tensors such as:
Scalar: A single number is a scalar. Scalar is a zero-order tensor.
Vector: One-dimensional array of numbers is a vector. Vector is a first-order tensor.
Matrix: Two-dimensional array of numbers is a matrix. Matrix is a second-order tensor
There are no words for higher dimensional arrays of numbers. All these n-dimensional data structures can be represented as tensors.
Does that mean tensors are just generalizations of scalars/vectors/matrices to higher dimensions?
Not quite. A tensor is a mathematical object that transforms according to certain rules under a change of coordinates. The mathematical object is an array of numbers. Why does it have to stay the same when we change coordinates? Because that's how deep learning models learn from the data.
If the data changes its characteristics when you change coordinates, then the deep learning models cannot learn. Or rather, whatever they learn will be incorrect because the data keeps changing its nature.
In deep learning, you usually need to deal with high dimensional data. This is best represented by tensors. It's a data structure that natively supports this type of representation. And it's very useful in building deep learning models.
How is it used in the real world?
Tensors have been around a long time. They first appeared in physics. They became part of machine learning in 2015. They have been used to build many modern systems that we use today. Real world data is converted to tensor representation so that deep learning models can learn from it. The resulting models are used in search engines, recommendation engines, face recognition, and more.
Since TensorFlow natively works with tensors, it optimizes its operations for both CPU and GPU usage. This has been a big win for deep learning. Google developed TPUs (tensor processing units) in 2016 to take it a step further. CPUs use bits (0s and 1s) to do calculations, but TPUs use tensor as a building block. This makes computations exponentially faster.
Where to go from here?
If you're building machine learning models, you'll be dealing with tensors a lot. It's good to have an understanding of how it works and why it's used. If you want to dig further, there's plenty of documentation available on how to use tensors in different scenarios. Keep building.
🔥 Featured job opportunities
You can check out Infinite AI Job Board for the latest job opportunities in AI. It features a list of open roles in Machine Learning, Data Science, Computer Vision, and NLP at startups and big tech.
💁🏻♀️ 💁🏻♂️ How would you rate this week’s newsletter?
You can rate this newsletter to let me know what you think. Your feedback will help make it better.