

Hey reader, welcome to the 💥 free edition 💥 of my weekly newsletter. I write about ML concepts, how to build ML products, and how to thrive at work. You can learn more about me here. Feel free to send me your questions and I’m happy to offer my thoughts. Subscribe to this newsletter to receive it in your inbox every week.

Within a data organization, we deal with many sources that generate data on a continuous basis. We need to extract data from these sources. And we need to load and transform this data so that we can create useful reports. These reports are consumed by people within the organization in order to make business decisions.
Even with this huge amount of data being generated, all these tasks need to be executed on time so that we can generate the output without any interruption. How do we coordinate these tasks and make sure that they are being executed?
Why do we need data orchestration?
Before there was data orchestration, data engineers would schedule tasks using a tool called "cron". It's a software utility to schedule tasks in Unix-based systems. If you automate a task using cron, it's called a cronjob. Building cronjobs that can handle large volumes of data started to get very complex. To solve this problem, the concept of data orchestration was introduced and popularized in the 2010s.
In an org, the data journey consists of going from raw data to human-readable reports. Each step in this journey is a task that processes the data in a certain way. The next task that needs to be executed is dependent on the situation. We might encounter many different situations along the way, which means we need to account for all different possibilities.
We need to stitch together a sequence of tasks to get the required output. This sequence of tasks is called a workflow.
A workflow management tool can evaluate the given scenario and route the data accordingly to the next task. Since data is voluminous and flows at high speed, we cannot do this manually. We need to programmatically make the decision at each step. How do we do that? Using the concept of data orchestration.
The tasks in a data pipeline will have interdependencies. It's necessary to have a system that can coordinate these dependencies and execute the tasks in order. We need this system to detect errors and generate alerts. Without such a system in place, it becomes difficult to verify if the generated results are reliable or not.
What exactly is it?
Data orchestration is the process of coordinating, executing, and managing these workflows. We bring together data from various sources, combine it, and make it available for use. It is driven by software, which means we need to run these workflows programmatically.
Is it the same as automation? Not really. They're closely related, but orchestration is not the same as automation. Automation is the process of getting a computer to perform a task. This task is usually repetitive in nature, which means it's not a good use of a human's time. On the other hand, orchestration is the process of coordinating the automation of number of tasks.
Let's take the example of an actual orchestra. It consists of a large group of musicians playing a variety of instruments. This group is usually led by a conductor who holds a baton and directs it by moving their hands. The conductor unifies the orchestra and guides the group. In this analogy, automation corresponds to the individual musicians playing their instrument and orchestration corresponds to the conductor unifying the group in a coherent way.
How does it work?
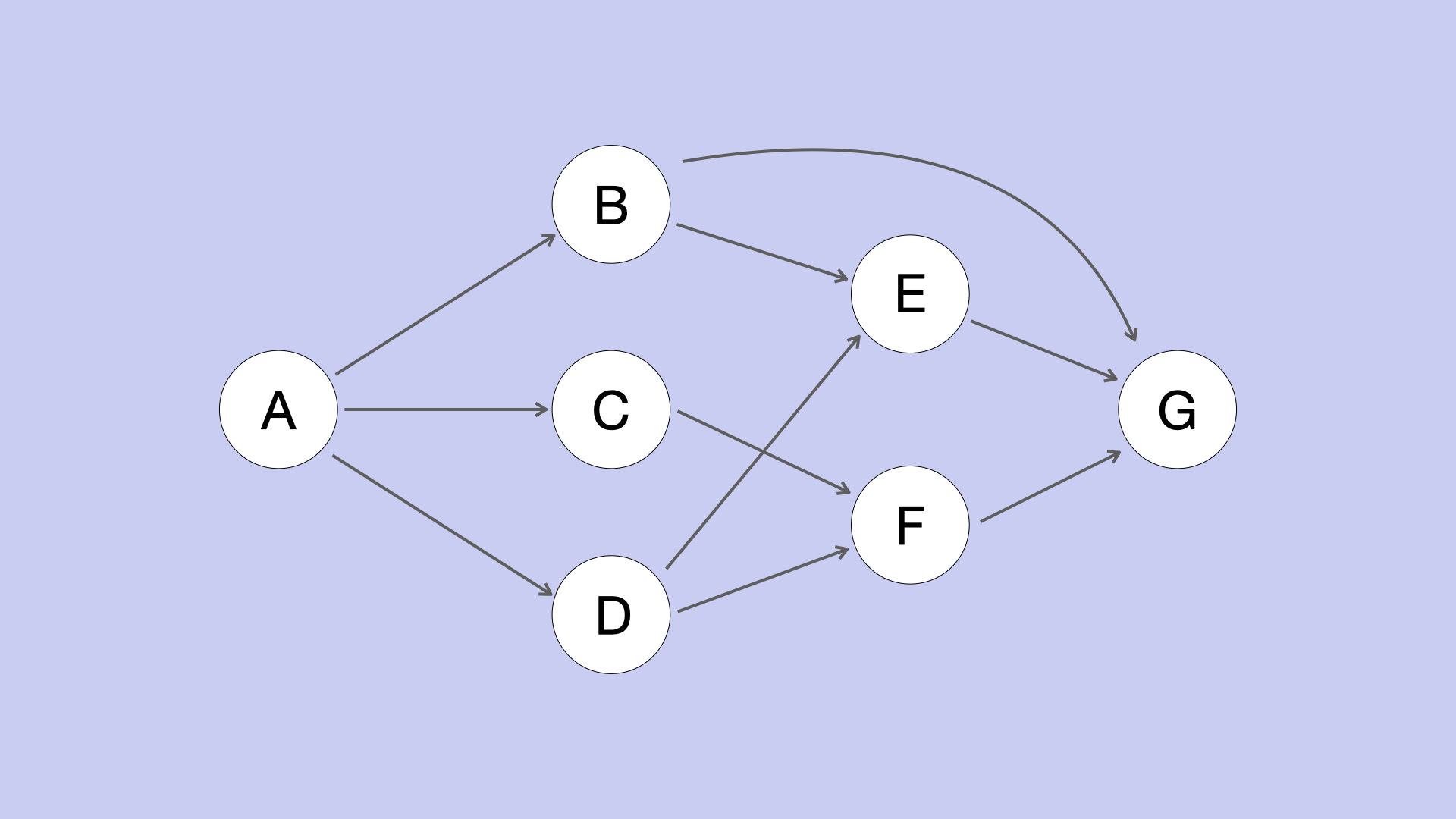
Modern data orchestration tools use the concept of Directed Acyclic Graph (DAG). This concept was introduced by Airflow and it has become very popular since then. DAG is actually a concept in mathematics that refers to a directed graph with no cycles.
A graph is considered "directed" if it specifies a direction for each edge. Let's consider two nodes 'A' and 'B' in the above graph. You can go from A to B, but not from B to A.
A graph is considered "acyclic" if there are no closed loops along any path. If we start at 'A' and traverse along the direction of the edges, we will never find a path that comes back to 'A'. It means there are no directed cycles. Hence the name Directed Acyclic Graph.
This structure is perfectly suited to run workflows. Each node specifies a task and the direction of an edge specifies how the data should flow. There's a starting node and an ending node, which guarantees that the data goes in and out of this system in a predictable way.
What tools are available?
There are many tools available for data orchestration such as:
Apache Airflow
Luigi
Dagster
Metaflow
Prefect
Flyte
Kedro
Astronomer
AWS Step Functions
Google Cloud Composer
Kubeflow Pipelines
Argo
Tekton
We'll talk about how these tools compare to each other in the next post.
How is data orchestration used in the real world?
Let's consider an ecommerce business. Every day at 5 pm, they need to generate a transaction report for the day. If we have a data orchestration system, it will generate this report for the entire organization at the scheduled time. It will extract data about sales, inventory, fulfillment, returns, and other pertinent data. This data is transformed and sanitized so that all the errors are removed. It's then sent to the data warehouse and then delivered to tools that people use to consume information.
All the modern technology products use data orchestration in some shape or form. Organizations that deal with enormous quantities of data tend to benefit from this. Companies such as Airbnb and Spotify pioneered the development of early data orchestration tools. Google, Amazon, and Microsoft have built these tools into their cloud platforms and made them available to all their customers.
Where to go from here?
There are many benefits to using data orchestration such as:
Making transaction data available to the internal org in a scheduled manner
Ingesting data streams continuously and keeping it ready for analysis
Reducing errors caused by humans when processing data
Increasing speed of product development
Data orchestration is an integral part of the modern data stack. If you work with data in any way, you'll end up using data orchestration sooner or later. This usually starts by writing scripts before realizing that you need a robust product to do this. You can get started by checking out the open source tools and making them part of your day-to-day work.
🎙🔥 Two new episodes on the Infinite ML pod
Che Sharma: We talk about experimentation, storytelling, reusable components, creating customer empathy, and data communities. Listen to it on Apple Podcasts or Spotify / Web.
Matt Kirk: We talk about quantitative economics, data science, writing books, being a zen student, surviving cancer, and using the pomodoro technique. Listen to it on Apple Podcasts or Spotify / Web.
📋 Job Opportunities in AI
Check out this job board for the latest opportunities in AI. It features a list of open roles in Machine Learning, Data Science, Computer Vision, and NLP at startups and big tech.
💁🏻♀️ 💁🏻♂️ How would you rate this week’s newsletter?
You can rate this newsletter to let me know what you think. Your feedback will help make it better.